spark-notes
This project is maintained by spoddutur
Spark as cloud-based SQL Engine for BigData via ThriftServer:
In this blog, You’ll get to know how to use SPARK as Cloud-based SQL Engine and expose your big-data as a JDBC/ODBC data source via the Spark thrift server. You can connect to ThriftServer using BI tools like Tableau, SQuirrel SQL Client and enable interactive data visualizations
Little bit background on other options to do the same before jumping into Spark:
Traditional relational Database engines like SQL had scalability problems and so evolved couple of SQL-on-Hadoop frameworks like Hive, Cloudier Impala, Presto etc. These frameworks are essentially cloud-based solutions and they all come with their own limitations as listed in the table below. Please refer to Appendix section at the end of this blog if you want to learn more on this

In this blog, we’ll discuss one more such Cloud-based SQL engine using SPARK and I’ll demo how to connect to it using Beeline CLI and as Java JDBC source with an example walkthrough.
Cloud-based SQL Engine using SPARK
Using Spark as a distributed SQL engine, we can expose our data in one of the two forms:
- In-Memory table - scoped to the cluster. Data is stored in Hive’s in-memory columnar format (HiveContext). For faster access i.e., lower-latency, we can ask Spark to cache it in-memory.
- Permanent, physical table - Stored in S3 using the Parquet format for data
Data from multiple sources can be pushed into Spark and then exposed as a table in one of the two mentioned approaches discussed above. Either ways, these tables are then made accessible as a JDBC/ODBC data source via the Spark thrift server. We have multiple clients like Beeline CLI, JDBC, ODBC, BusinessIntelligence tools like Tableau etc available to connect to thrift server and visualize our data. Following picture illustrates the same:
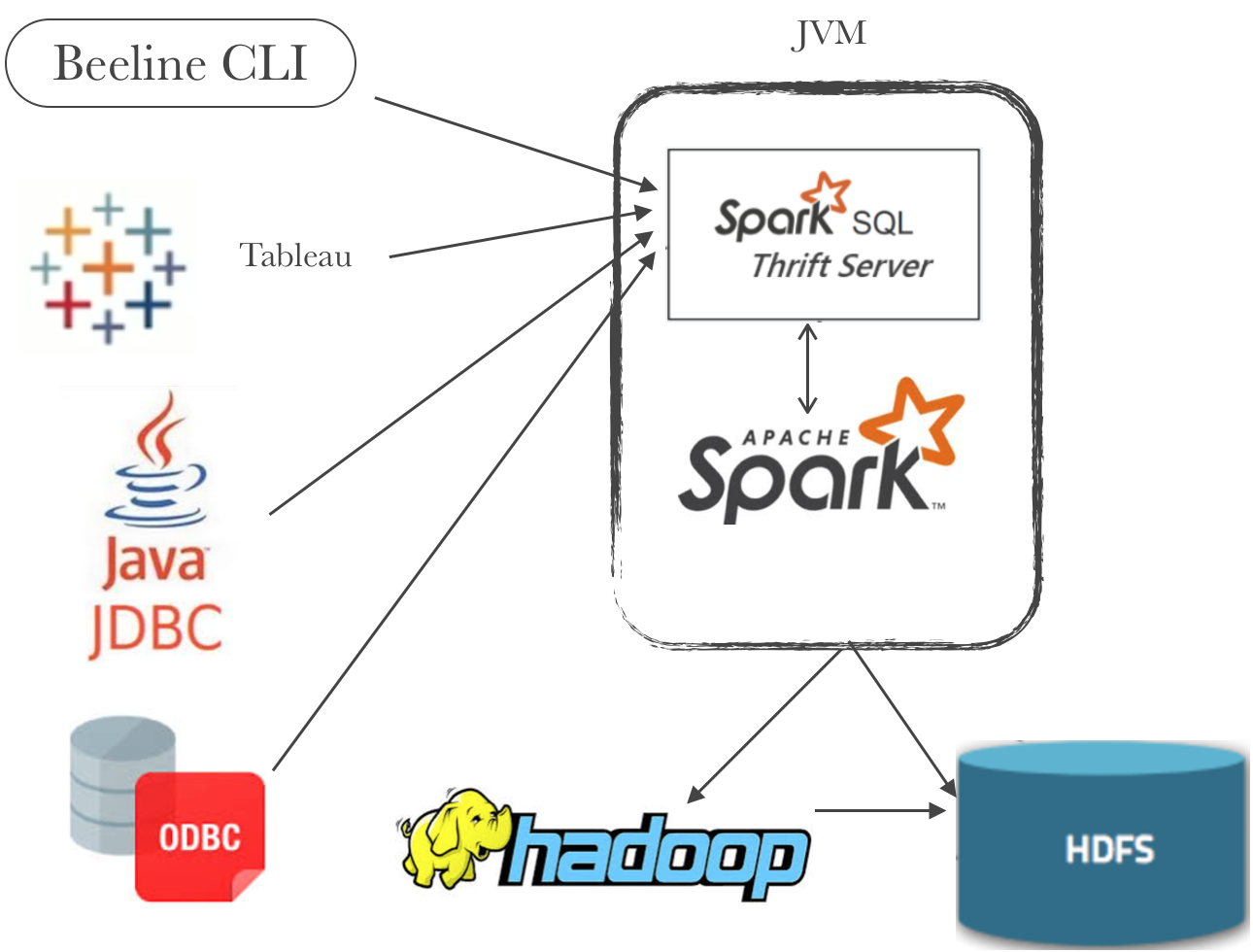
Spark Thrift Server:
Spark thrift server is pretty similar to HiveServer2 thrift. But, HiveServer2 submits the sql queries as Hive MapReduce job whereas Spark thrift server will use Spark SQL engine which underline uses full spark capabilities.
Example walkthrough:
Let’s walk through an example of how to use Spark as a distributed data backend engine
Code written in Scala 2.11 and Spark 2.1.x:
- For this example (to keep things simple), am sourcing input from a HDFS file and registering it as “records” table with SparkSQL. But in reality, it can go as complex as streaming your input data from multiple sources in different formats like CSV, JSON, XML etc, doing all sorts of computations/aggregations on top of your data and then register the final data as table with Spark.
// Create SparkSession
val spark1 = SparkSession.builder()
.appName(“SparkSql”)
.config("hive.server2.thrift.port", “10000")
.config("spark.sql.hive.thriftServer.singleSession", true)
.enableHiveSupport()
.getOrCreate()
import spark1.implicits._
// load data from '/beeline/input.json' file in HDFS
val records = spark1.read.format(“json").load("beeline/input.json")
// `As we discussed above, i'll show both the approaches to expose data with SparkSQL (Use any one of them):`
// `APPROACH 1: in-memory temp table names "records":`
records.createOrReplaceTempView(“records")
// `APPROACH 2: parquet-format physical table named "records" in S3`
spark1.sql("DROP TABLE IF EXISTS records")
ivNews.write.saveAsTable("records")
How to execute above code:
There are 2 ways to run above code:
- Using spark-shell:
- Start spark-shell using the below command.
spark-shell --conf spark.sql.hive.thriftServer.singleSession=true - This will open an interactive shell where you can run spark commands.
- Now, copy-paste above code line-by-line
- That’s it.. you just registered ur data with Spark.. Easy right :)
- Start spark-shell using the below command.
- Using spark-submit:
- Bundle above code as a mvn project and create jar file out of it.
- Once your mvn project it ready, do ‘mvn clean install’ and build JAR file.
- I have created cloud-based-sql-engine-using-spark git repository which bundled this code together with all the needed dependencies as a mvn project to download and run directly.
- Just download above repository and run it with following command:
// <master> can be local[*] or yarn depending on where you run. spark-submit MainClass --master <master> <JAR_FILE_NAME> - That’s it.. your data is registered with Spark!!
Once, data registration is over, you dont have to do any additional work to make this data available to outside world to query. Spark automatically exposes the registered tables as JDBC/ODBC source via Spark thrift server!!
Now, that our data is registered with Spark and exposed as JDBC source via Spark Thrift Server, let’s see how to access it..
Accesing the data
Perhaps the easiest way to test is using a command line tool beeline. I’ll show how to access data using beeline from within the cluster and from a remote machine:
1.Accessing the data using beeline - Within the Cluster:
- Connect to beeline.
beelineis an executable present in bin folder of$SPARK_HOME. We start beeline like this:`$> beeline` Beeline version 2.1.1-amzn-0 by Apache Hive - Within beeline, connect to spark thrift server @localhost:10000 (default host and port). This is the port we registered above. You can change this setting by tweaking
"hive.server2.thrift.port"="10000"config.// Connect to spark thrift server.. `beeline> !connect jdbc:hive2://localhost:10000` Connecting to jdbc:hive2://localhost:10000 Enter username for jdbc:hive2://localhost:10000: Enter password for jdbc:hive2://localhost:10000: Connected to: Apache Hive (version 2.1.1-amzn-0) Driver: Hive JDBC (version 2.1.1-amzn-0) 17/06/26 08:35:42 [main]: WARN jdbc.HiveConnection: Request to set autoCommit to false; Hive does not support autoCommit=false. Transaction isolation: TRANSACTION_REPEATABLE_READ - Once the connection is established, let’s test and see if our table
recordsis present..`jdbc:hive2://localhost:10000> show tables;` INFO : OK +-------------+ | tab_name | +-------------+ | records | +——————+------+ - Tht’s it!!! Your data is available as JDBC source! You can run any of the SQL commands you need on top of it..
Accessing the data using beeline - From a remote machine beeline:
This is exactly same as what we did above. Use beeline from any machine but instead of connecting to localhost spark thrift, we connect to remote spark thrift server like this:
`beeline> !connect jdbc:hive2://<REMOTE_SPARK_MASTER_IP>:10000`
Conclusion:
We've looked into:
- Different options available for SQL-on-Hadoop frameworks and their limitations
- How to use SPARK as Cloud-based SQL Engine to expose our data as JDBS/ODBC source via SparkThrift Server.
- An Example walkthrough on how to register data using
spark-shellandspark-submit - Tested our example using beeline both from localhost and remote machine
- Tested using Java JDBC approach as well
- You can connect to Thrift using BI tools like Tableau, SQuirrel SQL Client and enable interactive data visualizations.
References
- How to run queries on spark sql using JDBC via Thrift Server
- Apache Spark as a distributed sql engine
- Configure custom Thrift Server
- How to use SparkSession in ApacheSpark
- Use beeline to connect to Spark tables
Appendix:
- I ran the example code in amazon EMR cluster. If you are doing this in a stand-alone cluster or local-node managing it manually, then you will have to start Spark ThriftServer. This is how you start Spark ThriftServer:
- Set SPARK_HOME to point to your spark install directory
- Start ThriftServer in remote with proper master url “spark://IPADDRESS:7077” where 7077 is the default port of spark-master:
$SPARK_HOME/sbin/start-thriftserver.sh --master spark://<_IP-ADDRESS_>:7077 starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /Users/surthi/Downloads/spark-2.1.1-bin-hadoop2.7/logs/spark-surthi-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-P-Sruthi.local.out
- If you are interested in learning more details about other SQL-on-Hadoop frameworks like Hive, Impala, Presto etc.. this is a good link to refer to.