spark-notes
This project is maintained by spoddutur
Spark 2.x - 2nd generation Tungsten Engine
Spark 2.x had an aggressive goal to get orders of magnitude faster performance. For such an aggressive goal, traditional techniques like using a profiler to identify hotspots and shaving those hotspots is not gonna help much. Hence came forth 2nd generation Tungsten Engine with following two goals (focusing on changes in spark’s execution engine):
- Optimise query plan - solved via Whole-Stage Code-Generation
- Speed up query execution - solved via Supporting Vectorized in-memory columnar data
Goal 1 - Whole Stage Code Generation - Optimise query plan:
To understand what optimising query plan means, let’s take a user query and understand how spark generates query plan for it:
 Its a very straight forward query. Basically, scan the entire sales table and outputs the items where item_id =512. The right hand side shows spark’s query plan for the same. Each of the stages shown in the query plan is an operator which performs a specific operation on the data like Filter, Count, Scan etc
Its a very straight forward query. Basically, scan the entire sales table and outputs the items where item_id =512. The right hand side shows spark’s query plan for the same. Each of the stages shown in the query plan is an operator which performs a specific operation on the data like Filter, Count, Scan etc
How does Spark 1.x evaluate this query plan?
Ans: Volcano Iterator Model
Spark SQL uses the traditional database technique which is called Volcano Iterator Model.
This is a standard technique adapted in majority of the database systems for over 30years. As the name suggests [IteratorModel], all the operators like filter, project, scan etc implement a common iterator interface and they all generate output in a common standard output format. Query plan shown on the right side of the figure shown above is basically nothing but a list of operators chained together which are processed like this:
- Read the output generated by the parent operator
- Does some processing
- Produce the return value in a standard output row format.
- Hands over the return value to the next child operator
- Who is the child/parent of what is known only at runtime.
- Every handshake between 2 operators causes one virtual function call + reading parent output from memory + write the final output in memory
- In the example query plan shown on the right side of the above figure, Scan is the parent of the chain. Scan reads input data one-by-one, writes the output in main memory and hands it over to the next child which is Filter function and so on..
Downsides of Volcano Iterator Model:
Too many virtual function calls
- We don’t know where the child is coming from.
- Its all dynamic dispatching between parent and child operators at runtime.
- Its agnostic to the operator below it.
Extensive memory access
- There’s a standard row format that exists between all the operators and this means writes to main memory. Potentially, you read a row in and send a new row to your parent.This suffers from problems in writing intermediate rows to main memory.
Unable to leverage lot of modern techniques like pipelining, prefetching, branch prediction, SIMD, loop unrolling etc..
Conclusion: With VolcanoIterator Model, its difficult to get order’s of magnitude performance speed ups using the traditional profiling techniques.
Instead, let’s look bottom up..
What does look bottom-up mean?
A college freshman would implement the same query using a for-loop and if-condition like the one shown below:

Volcano model vs College freshman Code:
There’s ~10x speed difference between these 2 models

Why is the difference so huge?
College freshman hand-written code is very simple. It does exactly the work it needs to do. No virtual function calls. Data is in cpu registers and we are able to maximise the benefits of the compiler and hardware.
Key thing is: Hand written code is taking advantage of all the information that is known. Its designed specifically to run that query and nothing else VS volcano model is a more generic one

Key IDEA is to come up with an execution engine which:
Has the functionality of a general-purpose execution engine like volcano model and Perform just like a hand built system that does exactly what user wants to do.
Okay! How do we get that?
Answer: Whole-Stage Code Generation
- This is a new technique now popular in DB literature.
- Basically, Fuse the operators in the query plan together so the generated code looks like hand optimised code as shown in the below picture:
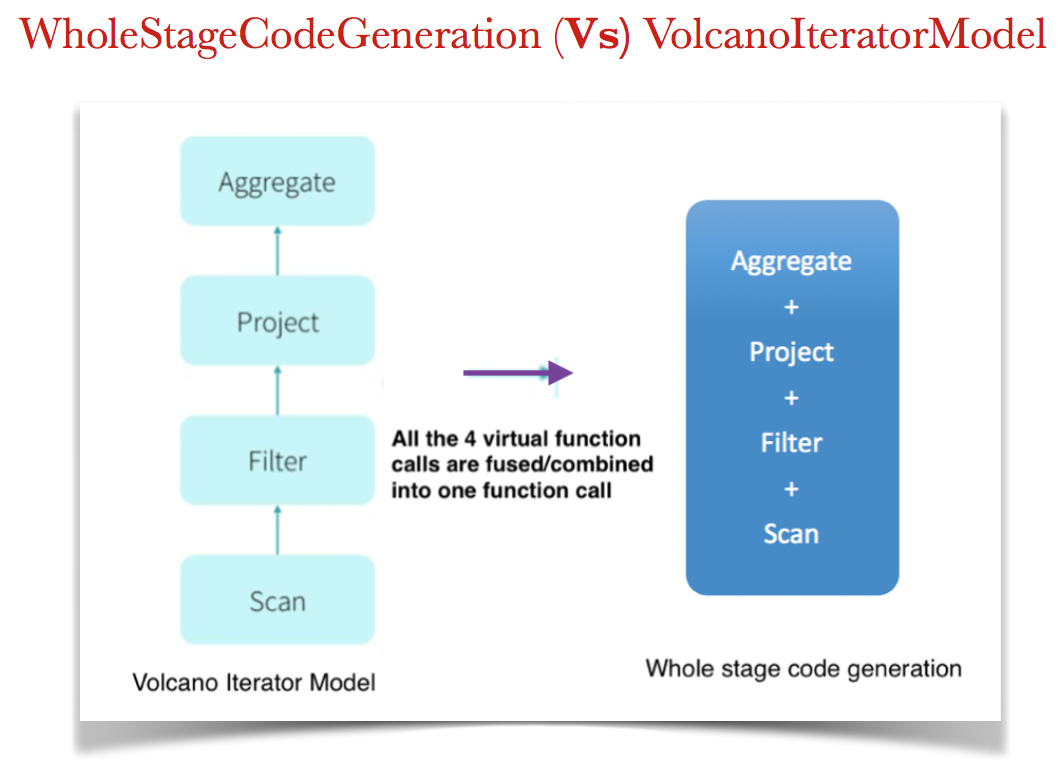
What does this mean?
- Identify chain of operators a.k.a stages
- Instead of having each operator as an individual function, combine and compile all of those stages into single function.
- At runtime generate the byte code that needs to be run
Let’s take another example..
Join with some filters and aggregation.
- Left hand side: shows how the query plans look like in volcano iterator model. There are 9 virtual function calls with 8 intermediate results.
- Right hand side: shows how whole-stage code generation happens for this case. It has only 2 stages.
- First stage is reading, filtering and projecting input2
- Second stage starts with reading and filtering input1, joining it with input2 and generates the final aggregated result.
- Here, we reduced Number of function calls to 2 and Number of intermediate results to 1.
- Each of these 2 stages(or boxes) is going to be converted into a single java function.
- There are different rules as to how we split up those pipelines depending on the usecase. We can’t possibly fuse everything into one single function.
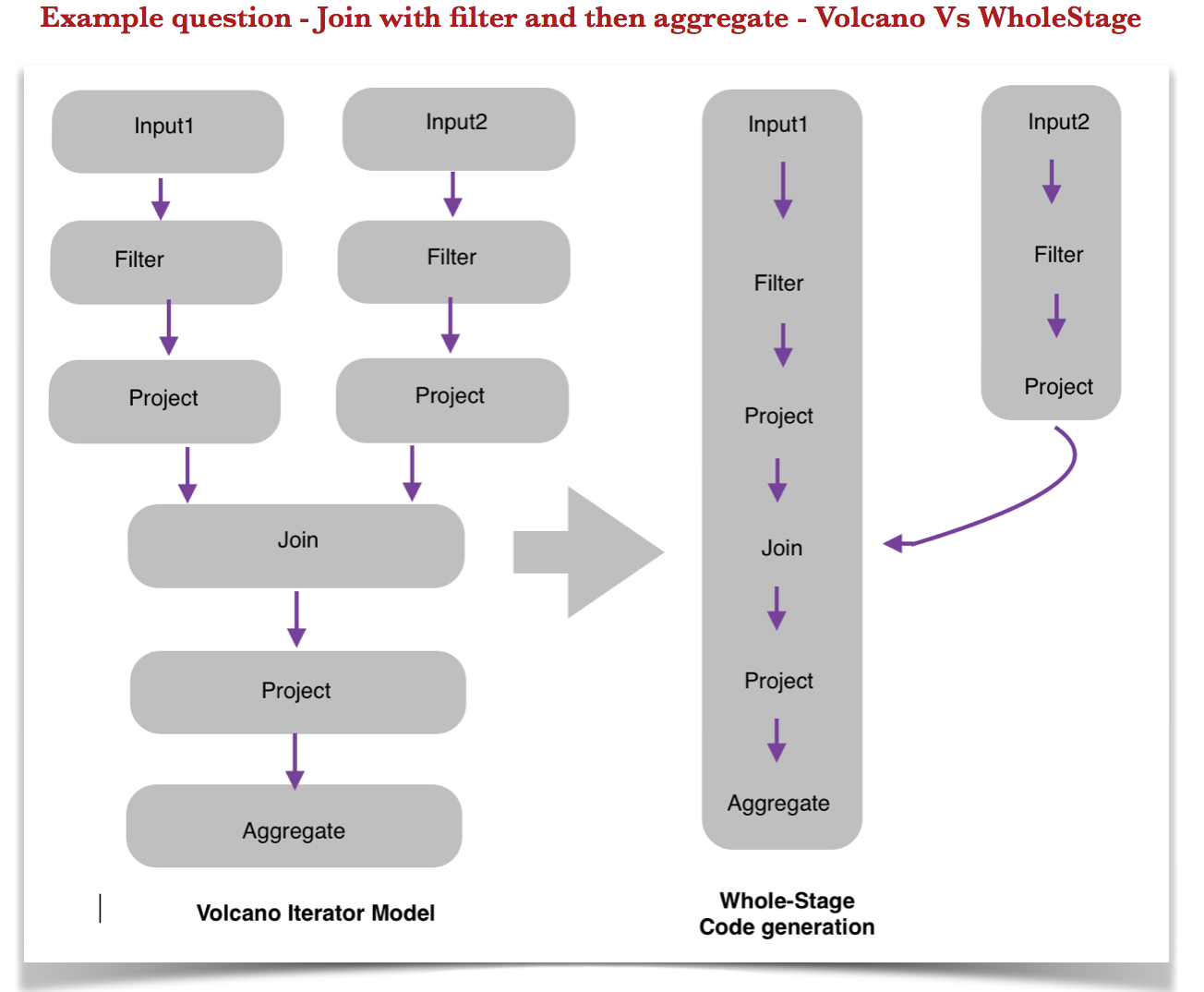
Observation:
Whole-stage Code Generation works particularly well when the operations we want to do are simple. But there are cases where it is infeasible to generate code to fuse the entire query into a single function like the one’s listed below:
- Complicated I/O:
- Complicated parsing like CSV or parquet.
- We cant have the pipeline extend over the physical machines (Network I/O).
- External Integrations:
- With third party components like python, tensor-flow etc, we cant integrate their code into our code.
- Reading cached-data
Is there anything that we can do to above mentioned stuff which can’t be fused together in whole-stage code-generation?
Indeed Yes!!
Goal 2 - Speed up query execution via Supporting Vectorized in-memory columnar data:
Let’s start with output of Goal1 (WholeStageCodeGeneration..)
Goal1 output - What did WholeStageCodeGeneration (WSCG) give us?
WSCG is generating an optimized query plan for user:
What extension can we add to this further?
This is where Goal2 comes into picture - Speed up query execution
How can we speed up?
Vectorization
What is Vectorization?
As main memory grew, query performance is more and more determined by raw CPU costs of query processing. That’s where vector operations evolved to allow in-core parallelism for operations on arrays (vectors) of data via specialised instructions, vector registers and more FPU’s per core .
To better avail in-core parallelism, Spark has done two changes:
- Vectorization: Idea is to take advantage of Data Level Parallelism (DLP) within an algorithm via vector processing i.e., processing batches of rows together.
- Shift from row-based to column-based storage format: We’ll discuss the details on what triggered this shift below.
Vectorization: Goal of Vectorization
Parallelise computations over vector arrays a.k.a. Adapt vector processing
Vectorization: What is Vector Processing?
Vector Processing is basically single instruction operating on one-dimensional arrays of data called vectors, compared to scalar processors, whose instructions operate on single data items as shown in the below picture:
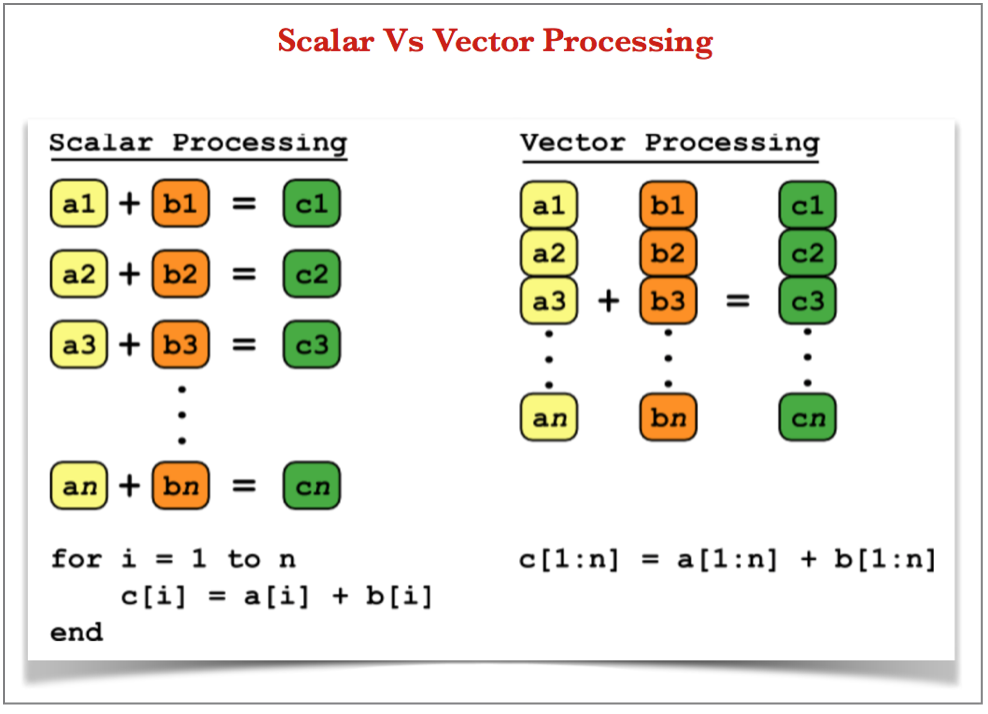
Vectorization: How did Spark adapt to Vector Processing:
-
Spark 1.x VolcanoIteratorModel performs scalar processing: We’ve seen earlier that in Spark 1.x, using VolcanoIteratorModel, all the operators like filter, project, scan etc were implemented via a common iterator interface where we fetch one tuple per iteration and process it. Its essentially doing Scalar Processing here.
-
Spark 2.x moved to vector processing: This traditional Volcano IteratorModel implementation of operators has been tweaked to operate in vectors i.e., instead of one-at-time, Spark changed these operator implementations to fetch a vector array (a batch-of-tuples) per iteration and make use of vector registers to process all of them in one go.
-
Ok, Wait..Vector register? What is it!? Typically, each vector registers can hold upto 4 words of data a.k.a 4 floats OR four 32-bit integers OR eight 16-bit integers OR sixteen 8-bit integers.
- How are these Vector registers used?
- SIMD (Single Instruction Multiple Data) Instructions operate on vector registers.
- One single SIMD Instruction can process eight 16-bit integers at a time, there by achieving DLP (Data Level Parallelism). Following picture illustrates computing
Min()operation on 8-tuples in ONE go compared to EIGHT scalar instructions iterating over 8-tuples: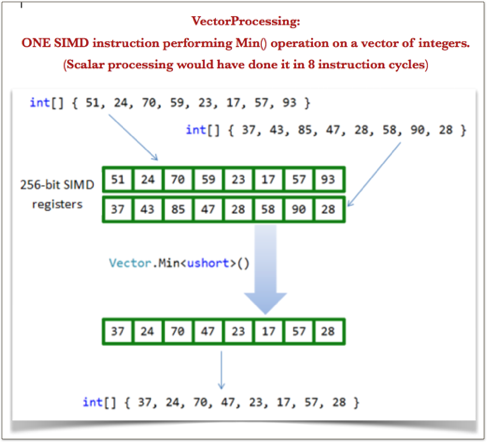
- So, we saw how SIMD instructions perform Vector operations. Are there any other ways to optimize processing? Yes..There’re other kinds of processing techniques like loop unrolling, pipeline scheduling etc ..(Further details on these are discussed in the APPENDIX section at the end of this blog)
Now, that we’ve seen what is Vectorization, its important to understand how to make the most out of it. This is where we reason out why spark shifted from row-based to columnar format
Row-based to Column-based storage format:
[Note: Feel free to skip this section if you want to jump to performace section and find out performance benchmark results]
What is critical to achieve best efficiency while adapting to vector operations?
Data Availability - All the data needed to execute an instruction should be available readily in cache. Else, it’ll lead to CPU stalling (or CPU idling).
How is data availability critical for execution speed?
To illustrate this better let’s look at two pipelines:
- One without any CPU Stall’s and
- The other with CPU Stall (CPU Idling)
Following four stages of an instruction cycle are displayed in the pipelining examples shown below:
- F Fetch: read the instruction from the memory.
- D Decode: decode the instruction and fetch the source operand(s).
- E Execute: perform the operation specified by the instruction.
- W Write: store the result in the destination location.
Pipeline without any CPU stall:
Following picture depicts an ideal pipeline of 4 instructions where everything is beautifully falling in-place and CPU is not idled:
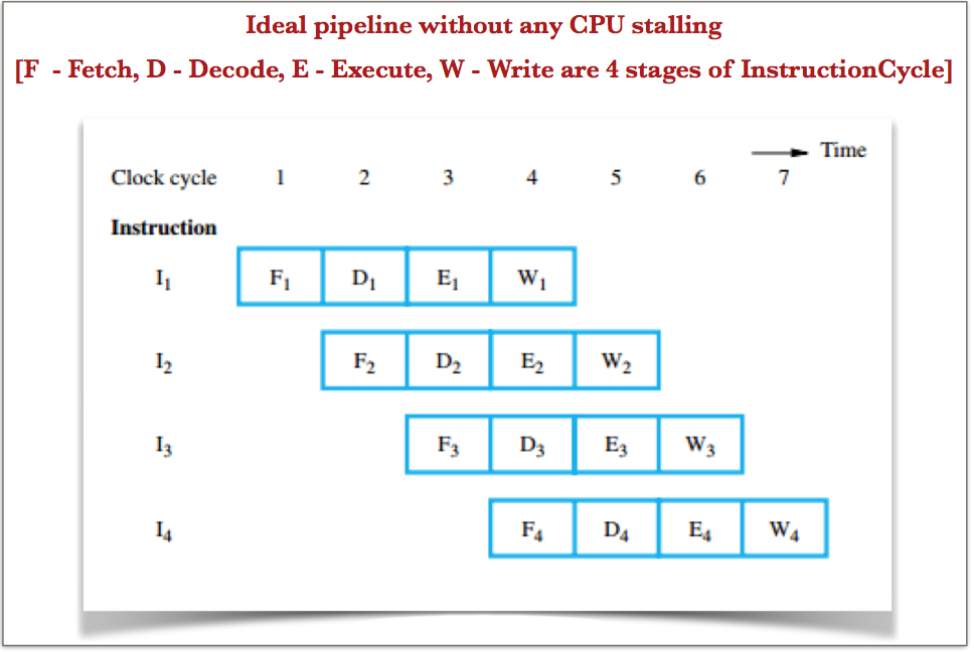
Pipeline with CPU stall:
Consider the same instruction set used in the above example. What if the second instruction fetch incurs a cache miss requiring this data to be fetched from memory? This will result in quiet some cpu stalling/idling as shown in the figure below.

Above example clearly illustrates how data availability is very critical to performance of instruction execution.
Goal2 Action Plan: Support Vectorized in-memory columnar data
- So, we’ve seen that any cache operation works best when the data that you are about to process is laid out next to the data you are processing now.
- This works against row-based storage because it keeps all the data of the row together immaterial of whether current processing stage needs only small subset of that row. So, CPU is forced to keep un-needed data of the row also in the cache just so it gets the needed part of the row.
- Columnar data on the other hand plays nicely because, in general, each stage of processing only needs few columns at a time and hence columnar-storage is more cache friendly. One could possibly get order-of-magnitude speed-up by adapting to columnar storage while performing vector operations.
- For this and many more advantages listed in this blog, Spark moved from row-based storage format to support columnar in-memory data.
Performance bechmarking:
- WholeStageCodeGeneration(WSCG) Benchmarking:
- Join and Aggregations on 1Billion records on a single 2013 Macbook Pro finished in less than 1 sec.
- Please refer to this databricks notebook where they carried out this experiment to join 1Billion records to evaluate performance of WSCG.
- Vectorised in-memory columnar support:
- Let’s benchmark Spark 1.x Columnar data (Vs) Spark 2.x Vectorized Columnar data.
- For this, Parquet which is the most popular columnar-format for hadoop stack was considered.
- Parquet scan performance in spark 1.6 ran at the rate of 11million/sec.
- Parquet vectorized in spark 2.x ran at about 90 million rows/sec roughly 9x faster.
- Parquet vectored is basically directly scanning the data and materialising it in the vectorized way.
- This is promising and clearly shows that this is right thing to do!!

Summary:
We’ve explored following in this article:
- How VolcanoIteratorModel in spark 1.x interprets and executes a given query
- Downsides of VolcanoIteratorModel like number of virtual function calls, excessive memory reads and writes happening for intermediate results etc
- Compared it with hand-written code and noticed easy 10x speedup!! Ola!!
- Hence came WholeStageCodeGeneration!
- But, WholeStageCodeGeneration cannot be done for complex operations. To handle these cases faster, Spark came up with Vectorization to better leverage the techniques of Modern CPU’s and hardware.
- Vectorization speeds up processing by batching multiple rows per instruction together and running them as SIMD instruction using vector registors.
- Conclusion: Whole stage code generation has done decent job in combining the functionality of general-purpose execution engine. Vectorization is a good alternative for the cases that are not handled by Whole-stage code-generation.
- Downside of Vectorization: Like we discussed in VolcanoIteratorModel, all the Intermediate results will be written to main memory. Because of this extensive memory access, where ever possible, Spark does WholeStageCodeGeneration first.
References:
- Spark Summit 2016 Talk on SparkPerformance
- Vectorization
- Databricks blog on Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop
- Loop Pipelining & Loop Unrolling
Appendix:
This is additional content (optional) which complements and adds some more details on different Optimization techniques which follow this key idea to improve throughput: The key to through put is organizing code to minimize jumps and organizing data to avoid cache misses, essentially avoid stalling or idling in the pipeline and achieve instruction level parallelism (ILP).
Few major approaches which follow above mentioned key note to achieve ILP:
- Pipelining
- SIMD (Single Instruction Multiple Data)
- Loop Pipelining
- Loop Unrolling
Vectorization - Pipelining:
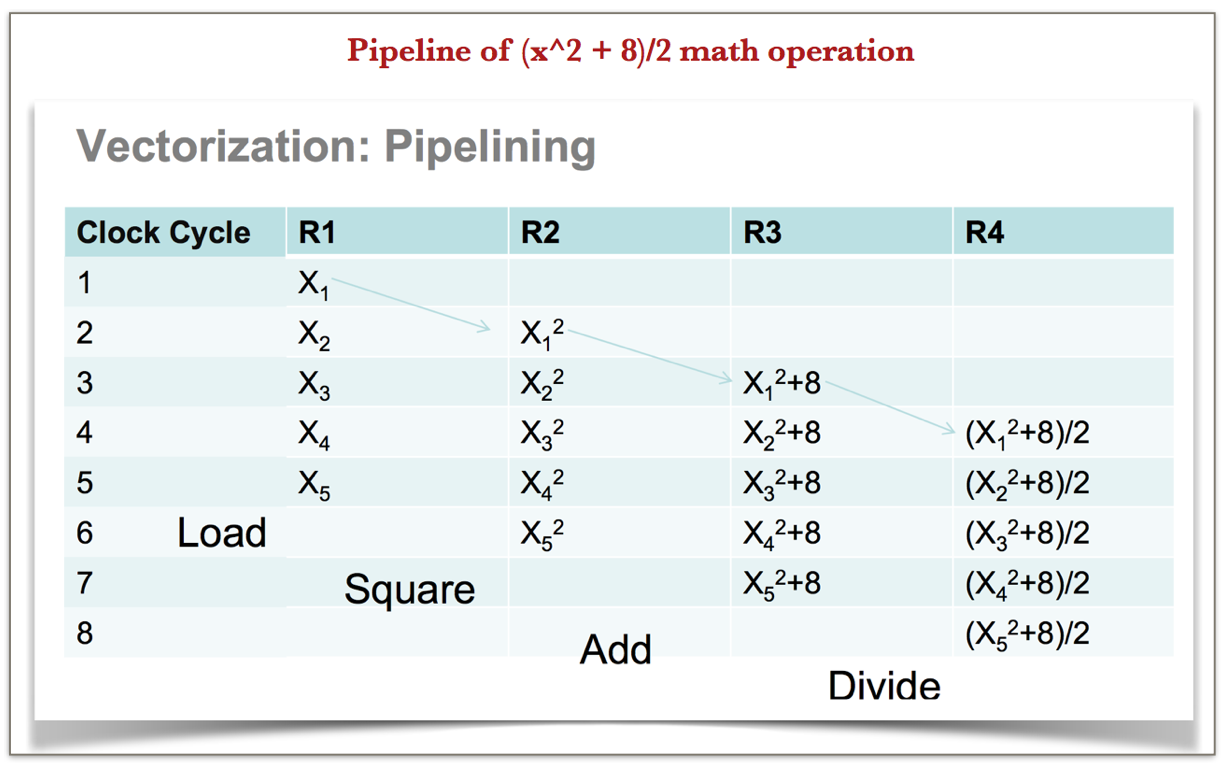
Pipelining execution involves making sure different pipeline stages can simultaneously work on different instructions keeping dependencies among the instructions in mind to avoid stalls and result in throughput increase.
An example of how pipelining happens for a simple math operation like (x^2 + 8)/2:
Vectorization - Single Instruction Multiple Data (SIMD):
Single Instruction Multiple Data (SIMD), as the name suggests, performs the same instruction/operation on multiple data points simultaneously.
Let’s look at how SIMD works on the same example (x^2 + 8)/2:

Loop Pipelining:
Loop pipelining allows the operations in a loop to be implemented in a concurrent manner as shown in the following figure.
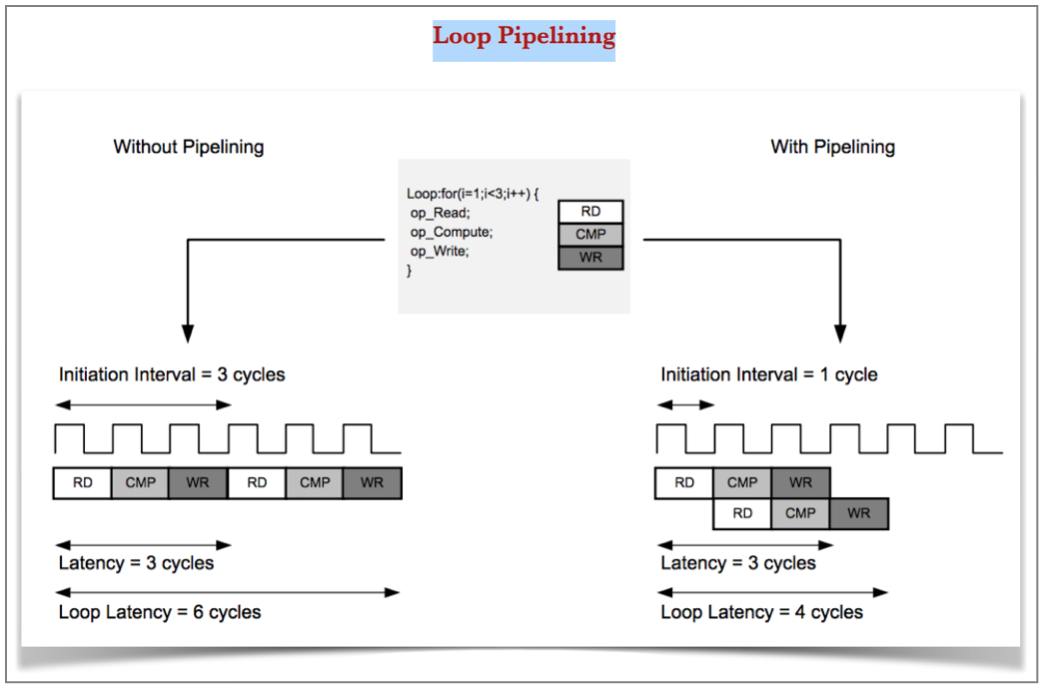
Loop Unrolling:
Loop unrolling is another technique to exploit parallelism between loop iterations. It identifies dependencies within the loop body, adjusts the loop iteration counter and adds multiple copies of the loop body as needed. Following table depicts 2 examples where loop unrolling is done.
